ScanCode LicenseDB -- 2,000+ licenses curated in a public database
· 4 min read
The ScanCode LicenseDB is all about identifying a wide variety of licenses that are actually found in software.
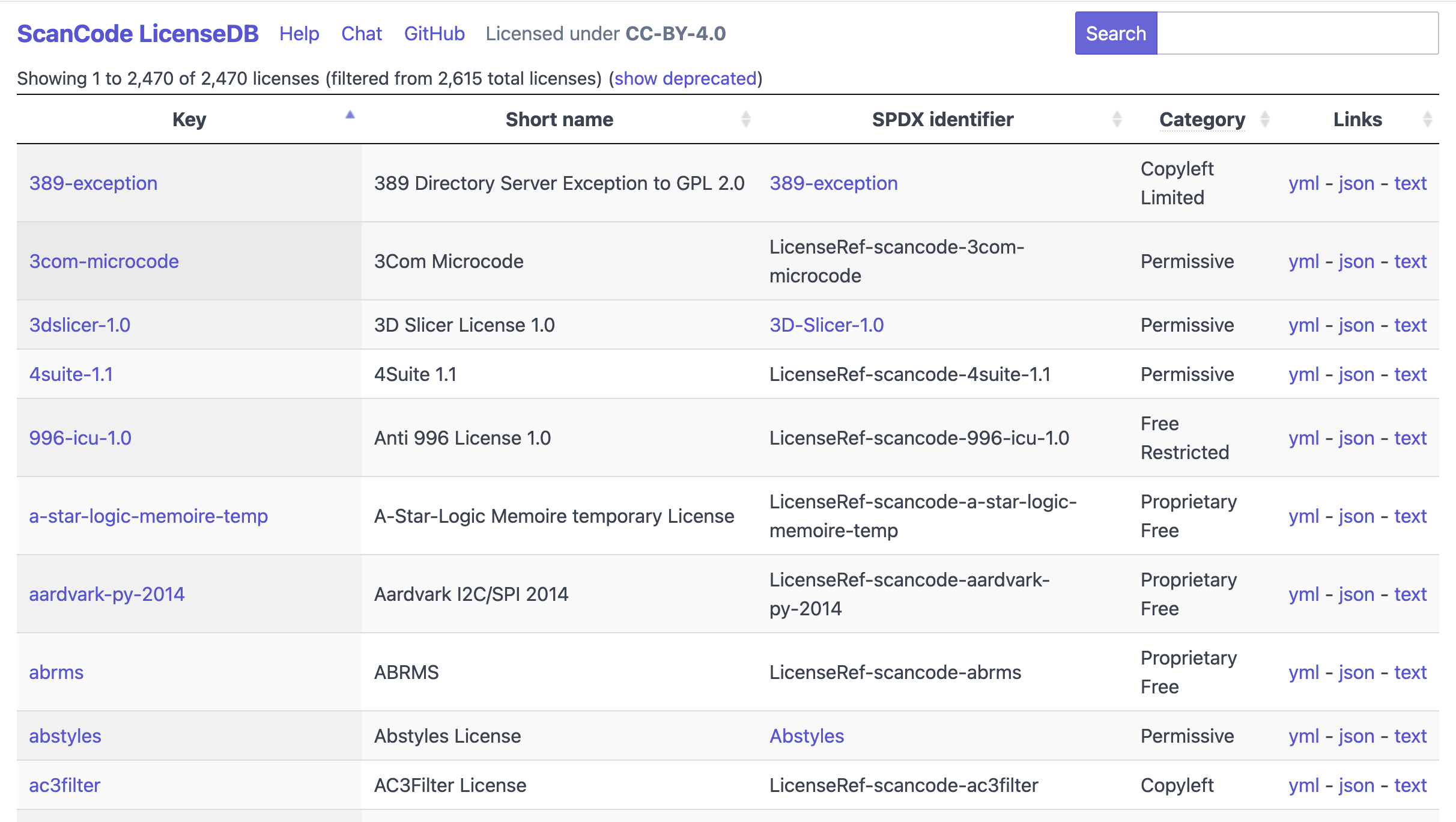
The ScanCode LicenseDB is all about identifying a wide variety of licenses that are actually found in software.
Make it easier for users and remove the word “Dual” from your software project notice vocabulary.

“This project is licensed under a Dual License of BSD and GPL.”
What does “Dual” mean in this context? In a practical sense, it means you have to dig more deeply into the licensing for that project to figure out what this license statement means:
Typically, but not always, this example statement means that you have a choice of BSD-3-Clause OR GPL 2.0 or later because these are the most common versions of those licenses. As the consumer of the software project you must conclude that interpretation and choice, usually after exploring the other license notices in the project files. You must declare that choice in the attribution of your project(s) or product(s) that use that software.
When automating SCA, License Clarity Scoring helps determine if scan results require more review.
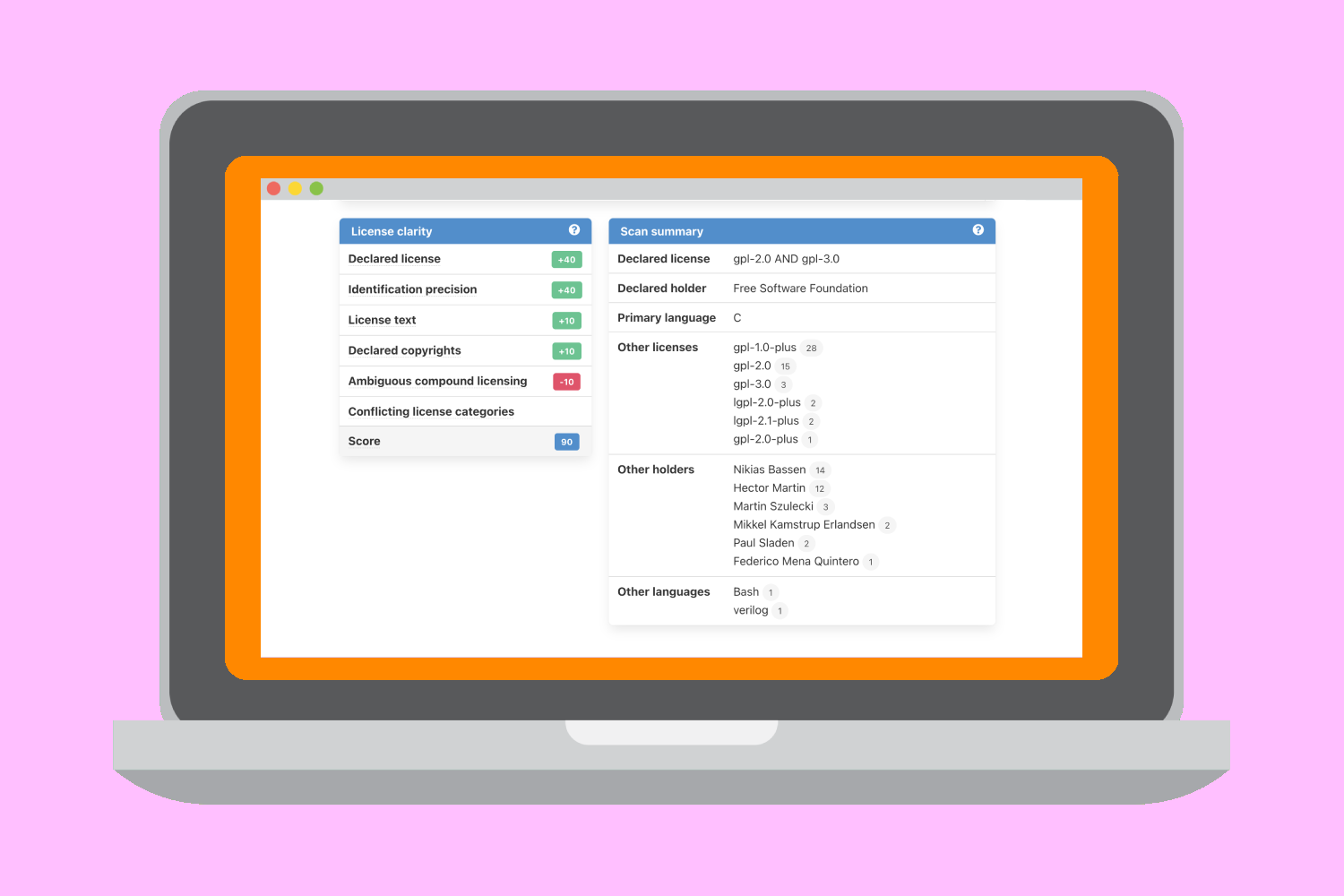
When automating Software Composition Analysis (SCA) with a scanning tool, you need to quickly evaluate the results – especially to determine whether or not the results require a deeper investigation.
ScanCode now includes License Clarity Scoring to provide users with a confidence level regarding the automated scan results.
Key considerations while using Copyleft-licensed software components in a Java application.

This document explains some key considerations for the use of Copyleft-licensed software components in a Java application in two contexts:
For this document, “JAR” refers specifically to an executable Java library that is a collection of .class files packaged into a file with the .jar extension; it does not refer to the use of a .jar file as an archive file only (such as for packaging source files for a Java library).
The purpose of this document is to present a “conservative” interpretation of what linking, or interaction may mean in the Java context. It is not based on any particular product or application and we are not aware of any specific license compliance enforcement actions in this area.