ScanCode LicenseDB -- 2,000+ licenses curated in a public database
· 4 min read
The ScanCode LicenseDB is all about identifying a wide variety of licenses that are actually found in software.
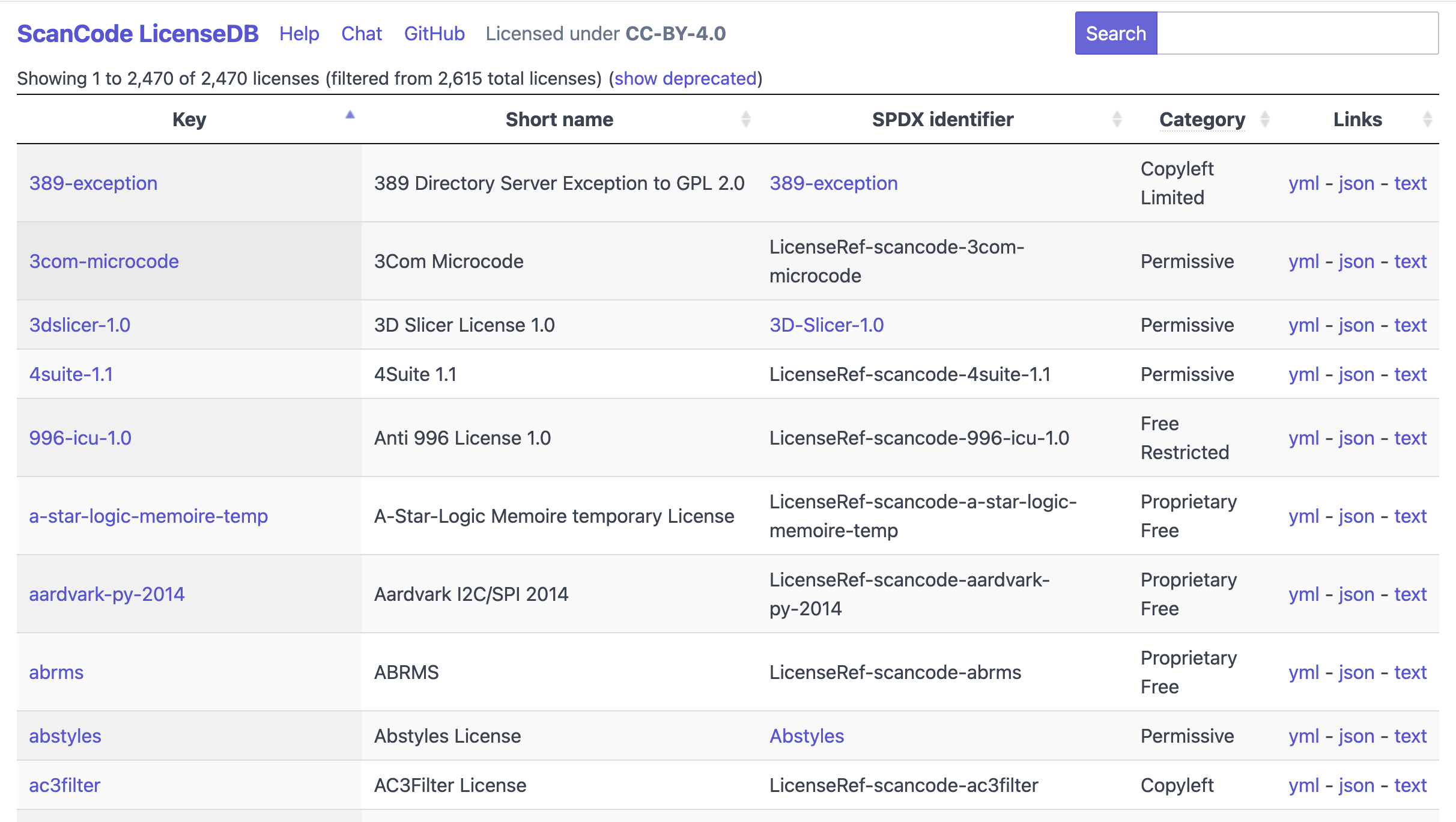
The ScanCode LicenseDB is all about identifying a wide variety of licenses that are actually found in software.

The AboutCode team is planning to deprecate the V1 and V2 API of VulnerableCode (public.vulnerablecode.io) by the end of Q2 2026 (June 20, 2026). We are introducing V3 API and UI by the end of January 2026.
The existing V1 and V2 APIs are both based on the “vulnerabilities” model, designed to aggregate information from multiple advisory sources based on identifiers and aliases. With the "vulnerabilities" model it is difficult to determine which source is correct because of the combination of sources. This may result in data from one source overwriting data from another source.

atom and chen, two open source tools for high-quality code analysis built by the AppThreat team, are now part of the non-profit AboutCode organization committed to making open source easier and safer to use by building critical open source tools for Software Composition Analysis (SCA) and beyond.
“AppThreat started with the simple mission to make high-quality code analysis and security tools for everyone,” says Prabhu Subramanian, lead maintainer of atom and chen, founder of AppThreat, and creator of other open source supply chain security tools like OWASP CycloneDX Generator (cdxgen), OWASP blint, and OWASP depscan.
Accurately identify third-party software packages with PURL.

If you need to generate (or consume) Software Bill of Materials (SBOMs), then you need a standardized way to communicate information about what components are in your software.
If you’re using or building applications, you need tools to determine if there are any known security issues with open source and third-party components.
Dependencies may come with vulnerabilities that can be exploited by attackers.
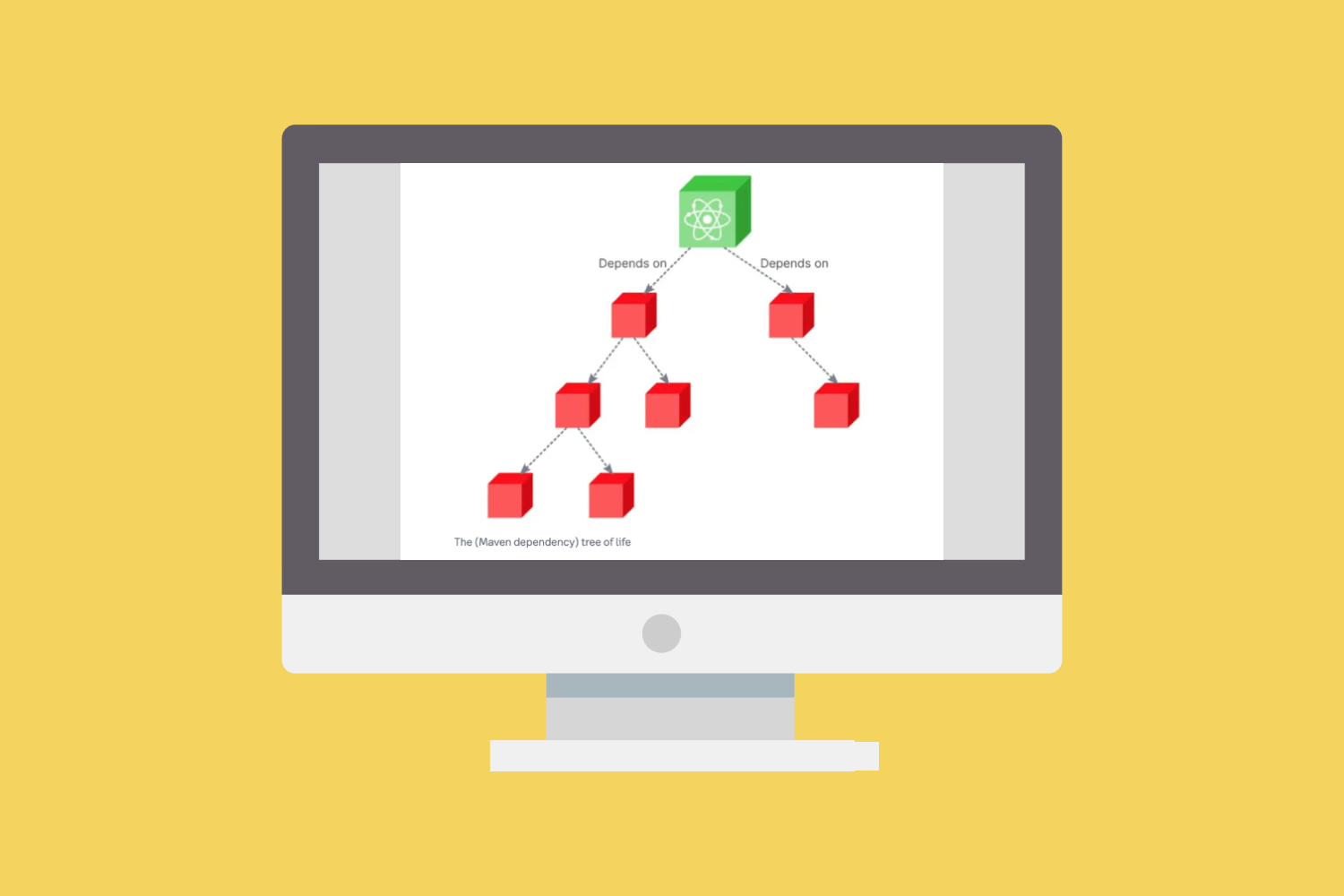
Dependency resolution is the process of identifying and installing the required software packages to ensure that the software being developed runs smoothly. However, these dependencies may come with vulnerabilities that can be exploited by attackers.
Until now, these contexts have been considered as separate domains:
Package management tools resolve the version expression of the dependent package of a package to resolved versions in order to install the selected versions.
Security tools check if resolved package versions are affected by known vulnerabilities (even when integrated in a package management tool)
As a result, the typical approach to get a non-vulnerable dependency tree is:
Make it easier for users and remove the word “Dual” from your software project notice vocabulary.

“This project is licensed under a Dual License of BSD and GPL.”
What does “Dual” mean in this context? In a practical sense, it means you have to dig more deeply into the licensing for that project to figure out what this license statement means:
Typically, but not always, this example statement means that you have a choice of BSD-3-Clause OR GPL 2.0 or later because these are the most common versions of those licenses. As the consumer of the software project you must conclude that interpretation and choice, usually after exploring the other license notices in the project files. You must declare that choice in the attribution of your project(s) or product(s) that use that software.
One software version control to rule them (modern software development) all?

Software projects make many decisions, but one of the most critical is deciding how to implement version control (also known as revision control, source control, or source code management). With modern software development, a versioning convention is a key tool to manage software releases and revisions. The two main approaches are calendar versioning (CalVer) and semantic versioning (SemVer), often with some alterations depending on an organization’s or project’s requirements.
For AboutCode projects, we started with SemVer, transitioned to CalVer and then migrated back to a format that mostly resembles SemVer. This blog post details the pros and cons of each version convention, along with explaining why we embarked on this version convention journey.
When automating SCA, License Clarity Scoring helps determine if scan results require more review.
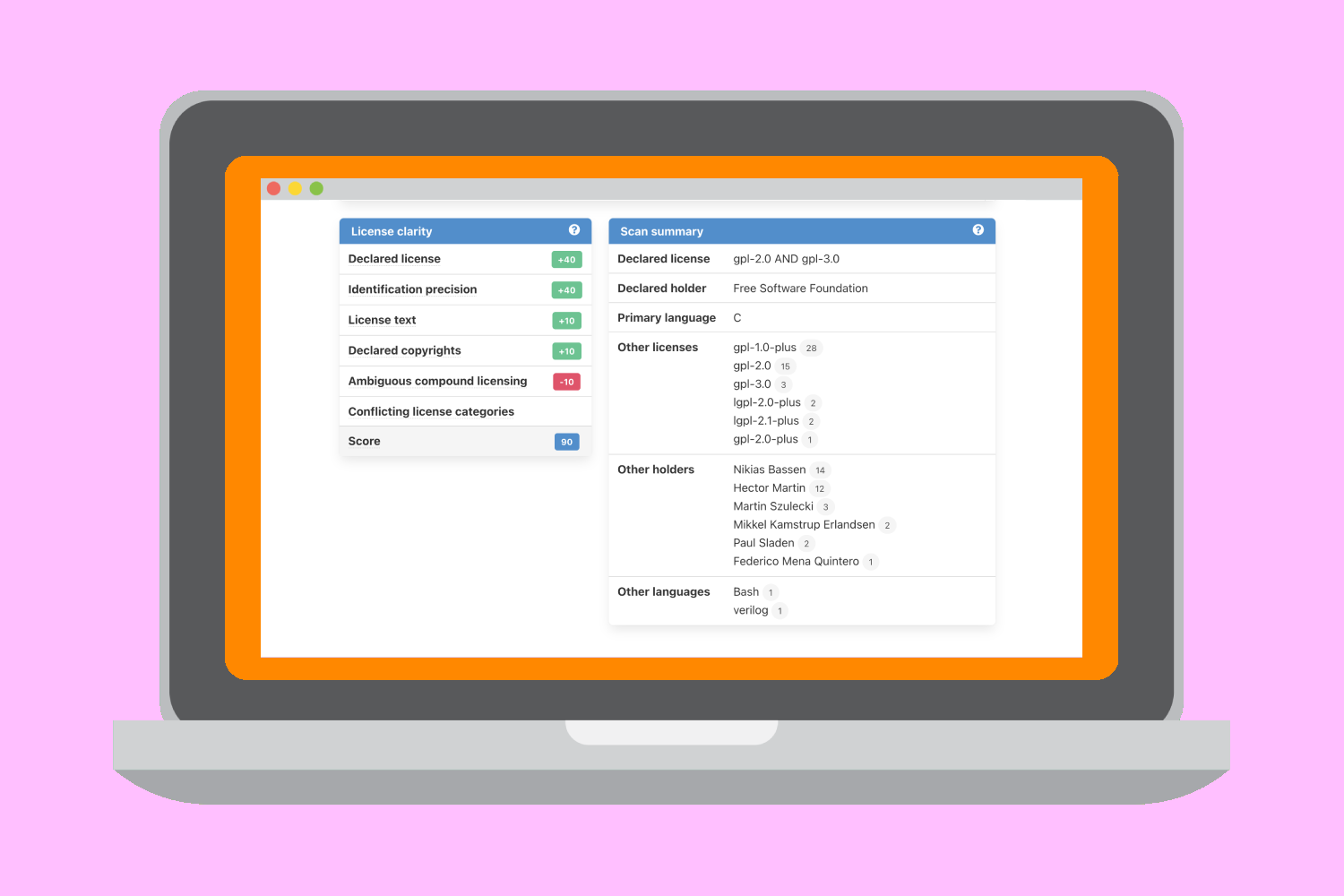
When automating Software Composition Analysis (SCA) with a scanning tool, you need to quickly evaluate the results – especially to determine whether or not the results require a deeper investigation.
ScanCode now includes License Clarity Scoring to provide users with a confidence level regarding the automated scan results.
Key considerations while using Copyleft-licensed software components in a Java application.

This document explains some key considerations for the use of Copyleft-licensed software components in a Java application in two contexts:
For this document, “JAR” refers specifically to an executable Java library that is a collection of .class files packaged into a file with the .jar extension; it does not refer to the use of a .jar file as an archive file only (such as for packaging source files for a Java library).
The purpose of this document is to present a “conservative” interpretation of what linking, or interaction may mean in the Java context. It is not based on any particular product or application and we are not aware of any specific license compliance enforcement actions in this area.