VulnerableCode API Deprecation and V3 Introduction
· 2 min read

The AboutCode team is planning to deprecate the V1 and V2 API of VulnerableCode (public.vulnerablecode.io) by the end of Q2 2026 (June 20, 2026). We are introducing V3 API and UI by the end of January 2026.
Why this new API
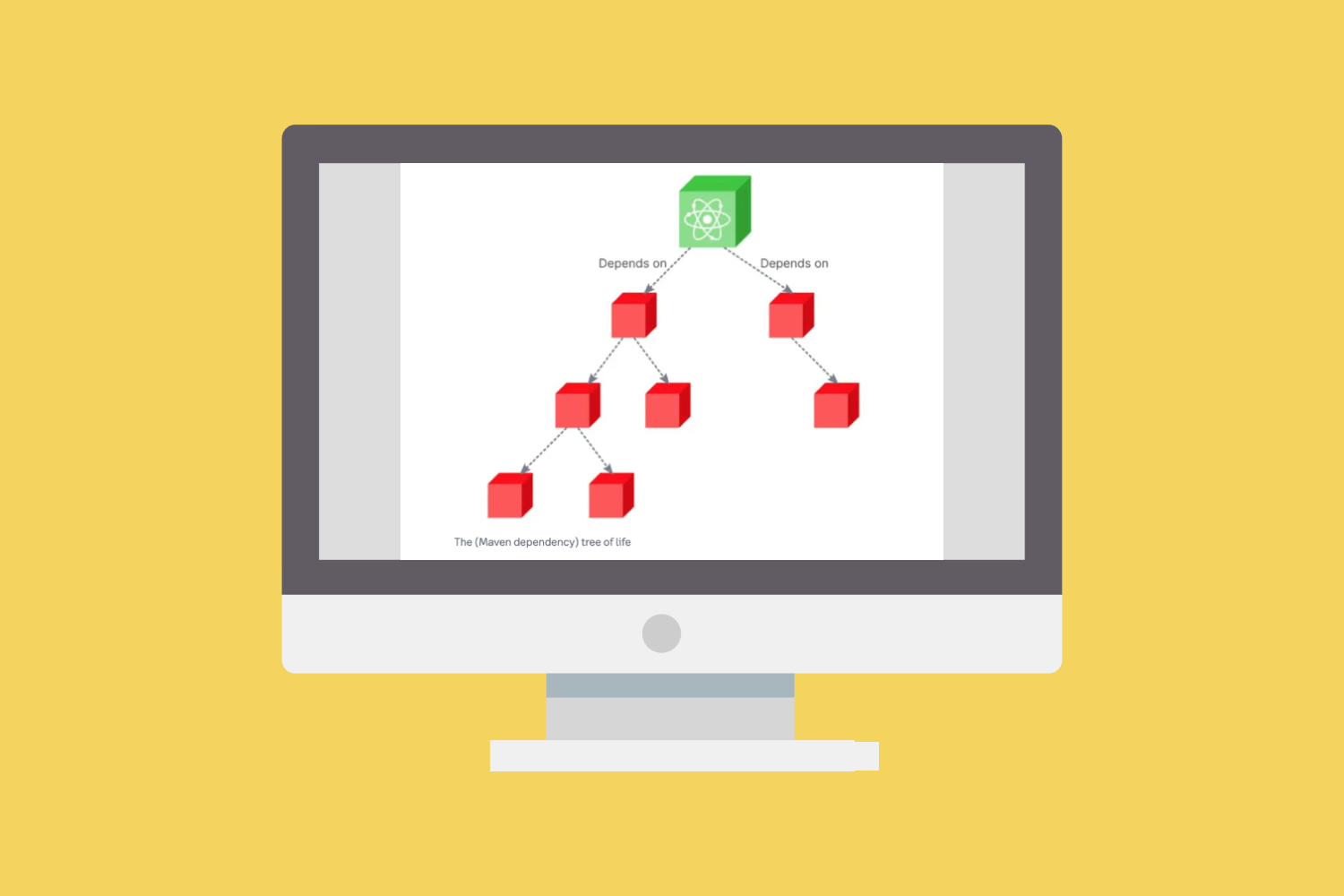
The existing V1 and V2 APIs are both based on the “vulnerabilities” model, designed to aggregate information from multiple advisory sources based on identifiers and aliases. With the "vulnerabilities" model it is difficult to determine which source is correct because of the combination of sources. This may result in data from one source overwriting data from another source.